

Collection
Using the Collection Column
The Collection column type lets you extract multiple structured items from a single document—such as all line items on an invoice or all board members in a contract—and store them in a dedicated, reusable table.
Unlike storing results inline (e.g., with JSON or Text columns), Collection columns split outputs into rows and columns, giving you clean, structured datasets ready for downstream use.
This extraction can be done using one of two tools:
- AI Tool (LLM) (Available) – ideal for parsing unstructured or semi-structured documents (e.g. contracts, letters, financial reports).
- Python Tool (Available soon) – best for structured documents or when you need deterministic logic (e.g. invoice tables, spreadsheets, recurring patterns).
When to Use the Collection Column
Use the Collection column when your extraction involves structured lists or repeatable items from a single source, especially when that data is best represented across rows.
A few examples below
| Use Case | Example | What It Enables |
|---|---|---|
| Extract tabular data from attachments | A contract contains 15 line items (product, quantity, unit price). | Output as rows for sorting, total calculation, or rate comparison. |
| Capture entity lists for dynamic analysis | Extract company executives from a corporate filing. | Filter by role, calculate tenure, or use results in downstream matching. |
| Extract yearly or multi-period figures | A PDF lists revenues from 2019 to 2024. | Creates time-series rows for trend analysis |
| Extract repeatable data from a single, unstructured document. | An investment report includes detailed valuations for each portfolio company. | Outputs one row per company, with fields for name, sector, valuation, and date. Enables filtering by sector, aggregating valuations, or comparing updates across periods. |
How to set up a Collection column ?
-
Add a new column and select
Collectionas the column type. -
Choose a column name. for the generated Collection Tab that will hold your extracted rows. Choose a short, descriptive name (e.g.,
management_table). -
Define the item names to extract (e.g., "revenue_value", "year"). These names define the structure of the child table and its columns.
-
Write the extraction instructions. This prompt will guide AI to extract the right items from the input document.
- Use clear instructions that refer to the item name defined in the previous step
- Do not forget to reference the column name from which AI must extract the items.
Extract each revenue year and its value from @document_name -
Launch the extraction by clicking Save and Update. to launch extraction. Phacet will begin populating the output table.
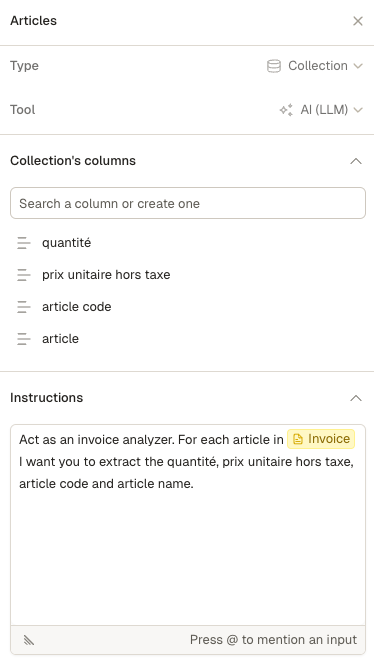
In this example we extract information for each article included in an invoice
Collection columns can only reference files (PDF) as the input source. It is not available for CSVs or structured columns.
Output Behavior and Access
Each Collection column creates a clickable link in your original table. Clicking it opens a Collection Tab where the AI-extracted rows are displayed.
You can view data in two ways:
- Per-document view – Click the cell in the Collection column to access extracted rows tied to that specific file. This is done by applying a filter to the full table.
- Full-table view – Open the Collection Table(bottom panel) to explore all extracted rows across documents.
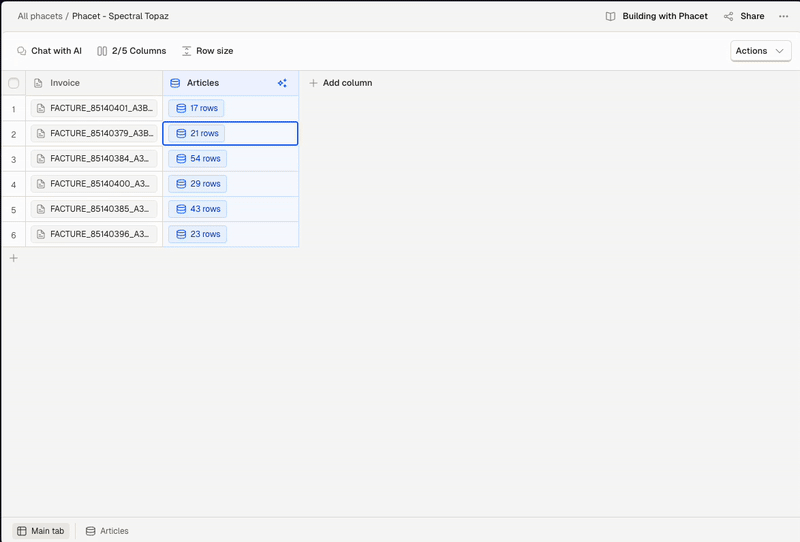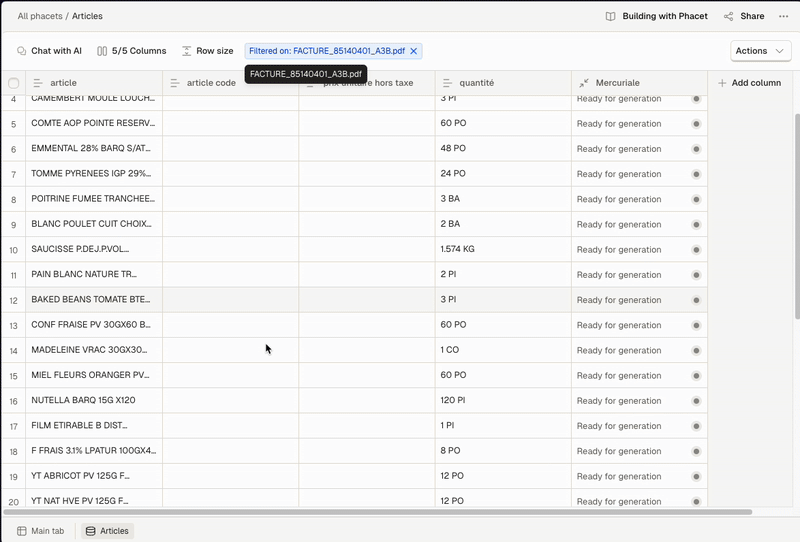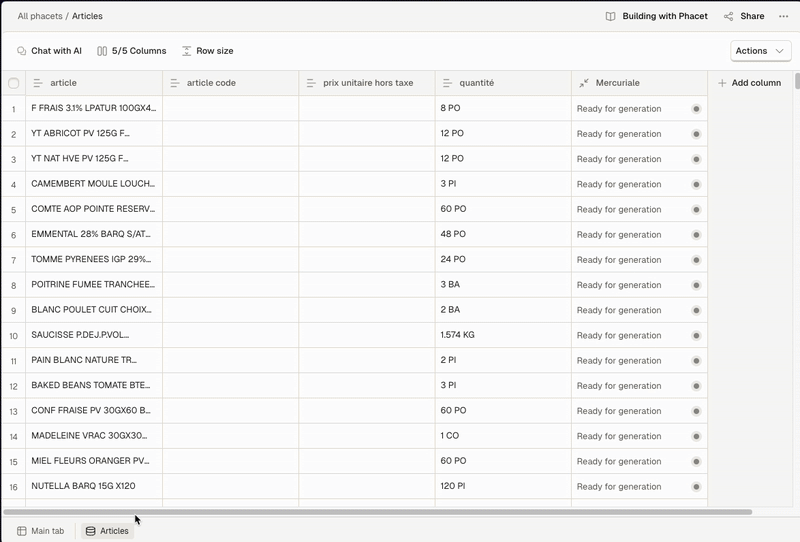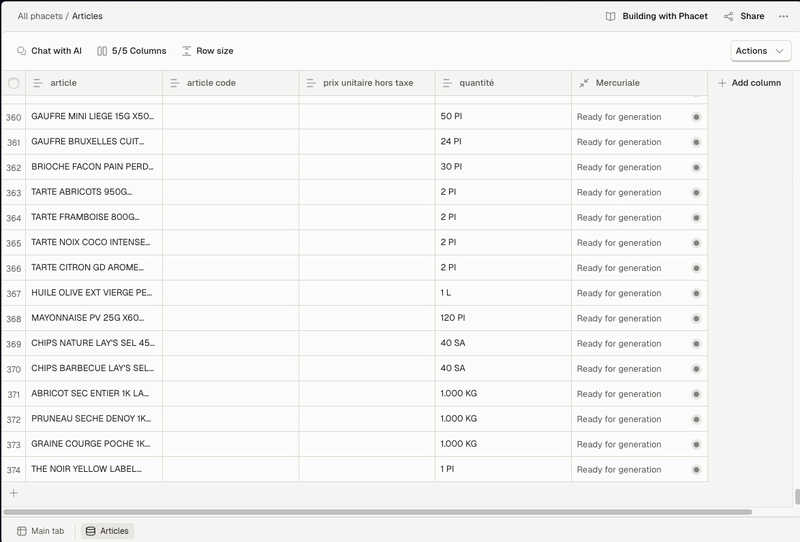
Illustration of per-document view and full-table view access
Work with extracted rows
The child table created by the Collection column is fully functional. You can:
- Add new columns, formulas, filters, or tags
- Run new AI Tool or Python Tool operations on each row
- Aggregate or summarize extracted values
- Reference extracted rows in another table using formulas.
This enables granular post-processing—sum amounts, filter by roles, or group by year—with the same flexibility as any Phacet table.
Collection vs other column types
Use this section to understand when to pick Collection over Matching, JSON, or Text column.
- vs JSON Column: JSON stores structured data in a single cell. Collection creates rows in a dedicated tab for better manipulation.
- vs Text: Text outputs one result per input row in a single cell. Collection extracts multiple outputs per document.
- vs Matching Column: Matching links input data to an existing dataset. Collection extracts new rows from source documents.
📚 Glossary
Quick definitions to clarify the core concepts used in the Collection column:
| Term | Definition |
|---|---|
| Parent Table | The original table where the Collection column is created. Each row in this table typically corresponds to one document. |
| Collection Column | A special column type that extracts and links multiple rows of structured data from a document. Each cell contains a clickable link to results. |
| Collection Table | The new table generated by the Collection column. It contains one row per extracted item and supports all standard table operations in Phacet. |